Requirement
Let me describe the problem as concisely as possible. We have a website on which we want to show analytics of the various clients of an org. The org has multiple clients all over India. The clients are categorized according to the regions they are located in, i.e, North, South, East and West. The org tracks certain parameters of it's clients. The org also requires the clients to update some details on a monthly basis and they have a track of these parameters in a database. We want to display the statistics of these parameters when a person from the org logs in to the website. The graphs we want to show club 3 different things:
- Year wise comparison
- Region wise comparison
- The parameter that is being compared
The Raw Data
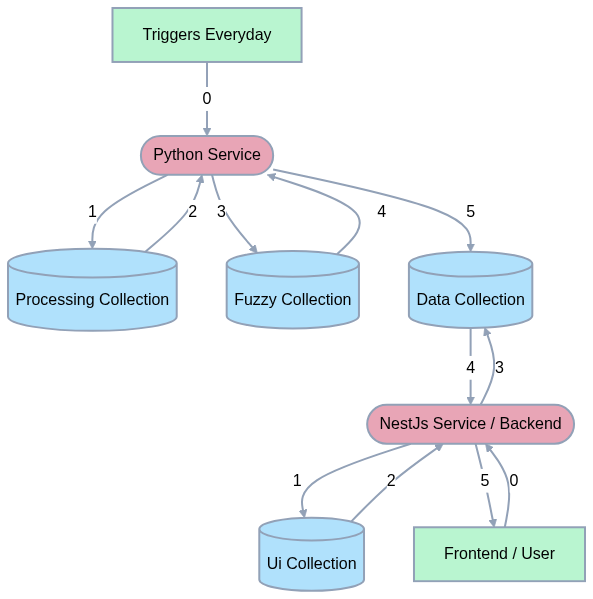
The raw parameters are stored very fuzzily in a MongoDB collection (let's call it fuzzy). Different parameters are nested at different levels within a document. So if we have to retrieve a parameter say p1, it would involve a query to the database that contains the path of the form:
foo1.foo2.foo3.foo4[0].p1,
and if we have to access another parameter p2 it may be a totally different path,
foo1.foo9.foo11.foo12[0].foo13[0].p2These parameters may update anytime between the month, that's because clients can update their details anytime between the month which gets reflected in this fuzzy collection. For our charts, different parameters need to be aggregated in different ways. Some have to be averaged to make sense and some have to be summed up to make sense.
To tackle this, we created a new collection where we would store information on how the data shoud be aggregated.
This collection had documents with fields like the path to the parameter and the operations that need to be performed to get the aggregated values.
Doing this would enable us to extend the aggregation with a custom function as well if the need arises.
Let's call this the Processing Collection.
A document in this collection would look something like this:
So for each document in the Processing Collection the python service hits the raw data in the Fuzzy collection and calculates the Average or some custom operation for presentable data.
Data Collection
There is a python service that is run as a cron job when the active user count is low, maybe around 3am in the morning. This python service pushes the processed data to the Data Collection for the ui to pick up when necessary. Documents here look something like this:
Ui Collection
We decided to use ChartJS because of it's wider user base and customizability compared to other chart rendering libraries. The Figma designs that we got from the PM included different kind of charts like stacked bar charts, scatter plots and such with different labels. So in this UI Collection, we stored things like x-axis label, y-axis label, type of chartJS chart, and the actual mongoDB query to access the raw data from the Data Collection. If a chart is showing 3 different parameters for 2 different regions, we would write the mongoDB query for the same to fetch from the Data Collection.
This data that is fetched is transformed into the required from using Lodash to supply it to ChartJS for rendering.